Processus métier scalable (arch)
De Wiki1000
Version du 20 janvier 2015 à 15:01 par Syfre (discuter | contributions)
Optimisation verticale versus Scalabilité horizontale
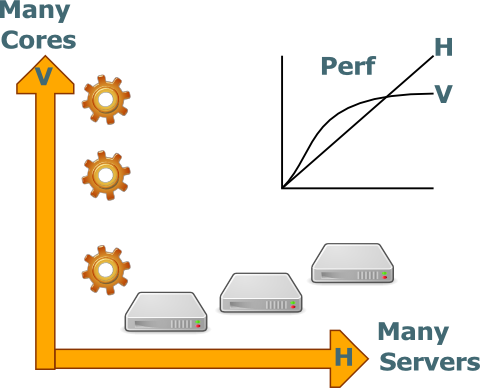
L'optimisation verticale consiste à exécuter le processus sur plusieurs cœurs simultanément.
- Elle permet d'optimiser l'utilisation des ressources d'un serveur.
- Elle permet d'augmenter les performances à couts constants.
- Elle permet d'augmenter les performances perçues par un utilisateur
Mais
- Elle est nécessairement limitée en scalabilité car la capacité en nombre de cœurs d'une machine est finie.
- Elle est complexe à mettre en œuvre.
- Elle est fragile.
- Elle nécessite du hardware premium.
- Elle est peut adapter à la virtualisation.
La scalabilité verticale consiste à exécuter le processus sur plusieurs serveurs simultanément.
- Elle permet de supporter l'augmentation de la charge par augmentation du nombre de serveur.
- Elle est théoriquement non limité.
- Elle permet d'utiliser du hardware standard.
- Elle est adapter à la virtualisation.
Mais
- Elle n'améliore pas les performances perçues par un utilisateur.
Modèle d'un processus métier
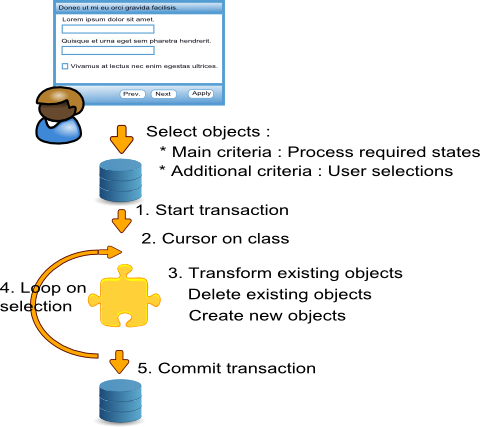
Le fonctionnement du processus :
- A partir de la sélection de l'utilisateur le processus construit un curseur sur la classe des objets à traiter.
- Le curseur filtre les objets sur :
- Les objets vérifiant l'état requis par le processus (par exemple les commandes livrables)
- Les objets vérifiant les sélections supplémentaires de l'utilisateur (par exemple les commandes du mois)
- Le processus démarre une transaction
- Le processus traite chaque objet retourné par le curseur
- Le processus commit la transaction.
Suivant les cas des variantes peuvent exister :
- Transaction unique pour l'ensemble de la sélection ou transaction objet par objet
- Regroupement des objets traités suivant des critères de rupture (par exemple les commandes d'un client)
Les problèmes avec ce modèle :
- Il n'est pas possible d'exécuter le processus simultanément sur plusieurs machines.
- Les différentes instances du processus s'exécuteraient sur les mêmes objets.
- Il n'est pas possible d'exécuter le processus au fil de l'eau
- La structure de traitement ne permet pas de dissocier facilement la sélection du corps du traitement
- Le traitement en une transaction unique limite le volume de donnée traitable.
Modèle d'un processus métier parallélisable
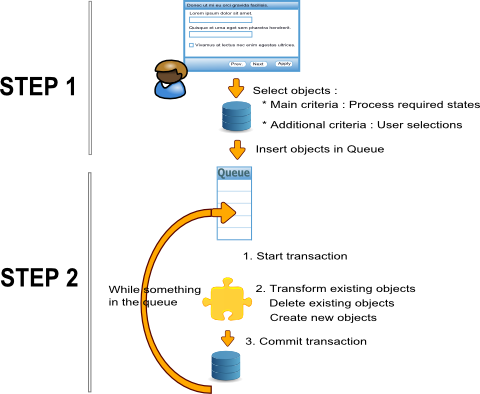
Ce modèle utilise une file d'attente pour stocker les objets traitables
- Dans une première étape les objets correspondant aux critères du processus et de la sélection sont insérés dans une file d'attente.
- Dans une seconde étapes les objets contenu dans la file d'attente sont consommés.
Les avantages de ce modèle :
- Il est possible d'exécuter simultanément plusieurs instances du processus, car :
- Il existe un critère d'unicité sur la file d'attente qui empêche d'inserer des objets en double.
- Un objet ne peut être consommé qu'une et une seule fois.
Exécuter plusieurs instances du processus doit permettre d'améliorer les capacités du processus en volume et en performance
- Il est possible de structurer le processus pour permettre une exécution au fil de l'eau
Les inconvénients de ce modèle :
- Il n'est pas possible d'exécuter un traitement dans une transaction unique.
- Il n'est pas possible de compter à priori le nombre d'objet à traiter
Voir aussi :
| Whos here now: Members 0 Guests 0 Bots & Crawlers 1 |